
This is a case study based on a piece of work we completed, but we have changed some of the details to keep our client's confidentiality. The piece in question involved reducing the overall costs for one of their platforms with minimal disruption. We also delivered the additional benefits of improving the team's ability to respond to bugs and better understand the load an environment could support.
This was an up and coming soon to be global system, running on Azure Kubernetes Service (AKS), using Helm to deploy a micro-service based application.
For those not familiar with Kubernetes this is container-orchestration platform, ideal for running micro-services. This oversees a pool of resources provided by backing virtual machines. The micro-services can then be automatically scaled out as demand increases, restarted if problems arise and are distributed across the backing virtual machines to give resilience.
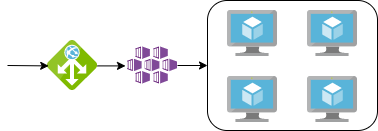
To support the development lifecycle a number of environments had been created. These were development, test, load-testing, staging and production environments.
When creating environments, it is important to only create what you need otherwise you incur monetary costs, and time costs supporting and maintaining additional environments.
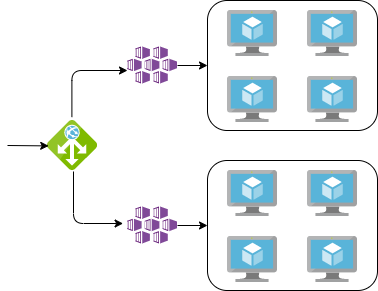
With these environments, two were configured as per the above architecture with 4 backing virtual machines, these were the development and testing environments. A further 2 were configured to be geographically load balanced, doubling the virtual machines to 8. These were the staging and production environments. The final environment, the load-testing environment, had been configured with 6 backing virtual machines, and again load balanced, leading to a total of 12 virtual machines!
So what does this mean for our costs? In this particular situation, the largest costs for each of the environments was the backing virtual machines and the web application firewalls protecting our applications and balancing load where these had been cloned to a second geographic region. For the initial configuration the environments were set to cost £6,650 a month, which equates to a massive £79,800 per year.
With the two biggest costs being the web application firewalls and the virtual machines, the question is can any of these be removed?
In the particular scenario, all of the environments were being used by members of the team and each fulfilled a distinct purpose, so no environments could be fully decommissioned. This prevents us from removing any of the web application firewalls. Although these are costly, security shouldn't be sacrificed for the sake of reducing costs.
For anyone looking for a cheaper alternative to the Azure V2 web application firewall, the version 1 web application firewall is still available, although this doesn't ship with zone redundancy and has a reduced feature set. This currently costs £85 p/m instead of the £250 p/m of the V2. Before making a selection always review your specific circumstances, and gain expert input if still in doubt.
This leaves the virtual machines backing our Kubernetes environments as one of the few cost variables we can adjust. The changes we can make here fall into two specific categories, to the size of the individual environments and to whether these environments are load balanced and doubling our costs.
One of the most important questions to ask when reviewing anything is "Why?. This enables a better understanding of the history of an implementation as well as checking the original rationale was correct, is still correct and is the implementation serving the purpose expected of it.?
So with our three load balanced environments, the rationale for the load balancing is that this is a global application. This means having the application load balanced between different geographic regions will provide an instance of the application closer to those using it resulting in a better experience, as well as geolocating user data based on data regulations and sovereignty laws, which we won't get in to now. So for the production environment, this was essential. The staging environment followed suit and mirrored the production environment to ensure like-for-like testing. The load-testing environment on the other hand was ripe for scrutiny.
The load-testing environment, had been scaled, and left running at a much higher capacity than production, 2 extra VMs in each of it's load balanced environments. This added a significant extra cost. This raised the question what was the benefit the load-testing environment was trying to provide? After some digging, it was clear this was to give an indication of the number of concurrent users the system could support. In its 6 v 6 load-balanced configuration the architecture was incorrectly scaled and configured to answer this question. Immediately the load testing environment was more powerful than the production environment meaning that any user concurrency numbers would be probably exceed the production environment by 30%. This is our first cost saving, reducing the total by around £600 p/m.
The second observation for the load-testing environment was that, due to the configuration on the load balancing, the load was distributed geographically although the load-testing team were only based in the UK. This meant that their load tests were not touching the second load-balanced environment. This was verified by checking the virtual machine utilisation. This permitted an entire AKS instance to be decommissioned. This further reduced the total costs by another £600 p/m.
The final change to the load-testing environment, was a change to the Kubernetes helm configuration. Due to the application being configured the same as in production, each of the micro-services comprising the application had varying numbers of themselves running. This had never been reviewed and there was no evidence to demonstrate the ratio of each micro-service required. To get a better grasp of the load at both the application and micro-service level it was suggested that each micro-service be limited to one instance. This also had the added benefit of giving a clearer indication of capacity as previously different instances of services had been failing at different points in the test. Having one, and only one, of each service permitted a better understanding of how much load each could support, while highlighting services that were weak links. By reducing the number of each micro-service running, this enabled the entire environment to be scaled back to just two backing VMs. Adding a further cost saving of £300 p/m.
Load-testing environment changes
- Scaling down the environment to match production.
- Turning off the second geographic region.
- Further reducing performance to provide a simpler testbed.
Saving: £1500 p/m
Development and Test Environments
Using our third strategy from the load-testing environment. We can reduce the number of each service running in our environments to one. This actually further improved the speed of testing as issues were easier to narrow down and isolate. The other advantage? Cost reduction. There's another saving of £600 p/m to be gained by scaling both the development and test environments.
While it's important to test systems work in their final working state, testing in simpler environments will allow the majority of issues to be resolved with much less effort. In this instance the staging environment allows the testing of micro-services at production scales ensuring there are no conflicts or issues running multiple instances of services in parallel.
Saving: £600 p/m
Results
The main result the customer was looking for is the reduction in cost. After our first pass, detailed above, monthly spend was reduced by £2,100. Overall, a saving of £25,200 a year.
In addition, we've made changes giving the software team the following improvements:
- Finding faults is easier when you are only looking at one instance of a service.
- Finding the performance threshold is easier when the environment is scaled down.
While this architecture may seem expensive, it's worth noting that more advanced architectures have a higher entry cost. But will potentially scale better in the long run. It is up to you to decide how you plan to launch your product but if you would like any advice, please feel free to reach out. There are a lot of differing factors, from budgets to timescales, that will govern a successful strategy.
Further Steps
Additional recommendations that were provided for this specific application focused on reserving hardware for a set period. If the hardware is definitely going to be used for an extended period, this enables discounts to be had by prepaying. This does remove any flexibility the cloud may have offered. In this instance, pre-buying for 1-year would save an additional £1300 per month, or over 3 years £2000 per month. This would come in as an annual saving of either £15,000 or £24,000 a year respectively. Giving a total recommended saving of over £50,000 a year or a cost reduction of 62.5%.